Archivio
Open data e Open service basati su standard: come ottenere lo shapefile dei Numeri Civici Open Data della Regione Sicilia partendo dai servizi resi disponibili
Tutto è nato da una mail di Andrea Borruso, apparsa sulla lista GFOSS proprio alla vigilia di Natale, in cui si annunciava, da parte della Regione Sicilia e per una serie di comuni, la disponibilità, in modalità WFS, di un dataset dei numeri civici georiferiti.
I servizi sono fruibili direttamente da client diversi, desktop, web, mobile, ecc …. che ovviamente supportino lo standard OGC WFS, cosa oramai ampiamente diffusa, piuttosto facile da fare e alla portata di un’utenza, seppur tecnica, piuttosto ampia.
Con una chiamata standard è anche possibile avere l’elenco dei comuni per cui sono disponibili i dati dei numeri civici: la chiamata è la seguente:
ogrinfo -ro wfs:"http://map.sitr.regione.sicilia.it/ArcGIS/services/CART_2000/Numeri_Civici/GeoDataServer/WFSServer"
Bello ma, per il mio interesse cioè quello di raccogliere i civici open data disponibili sul panorama nazionale, mancava una visione di insieme che mi fornisse TUTTI i civici a livello regionale.
Ma, essendo tutto basato su standard, si trattava solo di avere un po di voglia e tempo per fare un interessante (??? 🙂 ) esercizio informatico e “rinfrescare” alcune conoscenze messe un po’ da parte negli ultimi tempi.
Provo a riassumere quanto fatto, primo per mie note personali, ma anche perchè credo / spero possa interessare a chi voglia /debba poter replicare un’esigenza analoga.
Premetto che quello indicato NON è l’unico modo possibile per raggiungere l’obiettivo, ve ne possono essere diversi altri, anche più “eleganti”.
In tutto è organizzato in 3 passi logici.
Step 1: scaricare i dati collegandosi ai servizi
Nota organizzativa: gli eseguibili shell che illustro nel seguito operano nel rispetto di questa organizzazione su file system:

I servizi sono esposti in WFS e quindi possono essere contattati via chiamata http ottendo in risposta, tra le altre cose, il dato in formato GML.
Purtroppo gli attuali servizi non permettono di ottenere i dati in formati diversi.
In questo caso, essendo 376 i comuni da scaricare, e quindi le chiamate da fare, ho creato un piccolo eseguibile shell, lanciabile da linea di comando, che, usando il comando CURL disponibile in ambiente Linux e/o Windows a seconda delle installazioni (nel mio caso ho utilizzato CygWin …), scaricherà, completamente, tutti i singoli GML, uno per ogni comune.
La chiamata, per un singolo comune è la seguente …
curl "http://map.sitr.regione.sicilia.it/ArcGIS/services/CART_2000/Numeri_Civici/GeoDataServer/WFSServer?SERVICE=WFS&VERSION=1.0.0&REQUEST=GetFeature&TYPENAME=CART_2000:NumeriCivici_81008_Erice&SRSNAME=EPSG:4326" -o CiviciComuniSicilia/GML/81008_Erice_4326.gml
Visto che i comuni erano molti ho realizzato un programmino shell, denominato DownloadCiviciByCurl.sh, reso parametrico ….
echo "Download civici $1 ......"
curl "http://map.sitr.regione.sicilia.it/ArcGIS/services/CART_2000/Numeri_Civici/GeoDataServer/WFSServer?SERVICE=WFS&VERSION=1.0.0&REQUEST=GetFeature&TYPENAME=CART_2000:NumeriCivici_$1&SRSNAME=EPSG:4326" -o CiviciComuniSicilia/GML/$1_4326.gml
echo "Sleeping for 30 sec: don't load too much the server ...."
sleep 30
il quale è poi richiamabile da un programmino di lancio denominato LauncherDownloadCiviciByCurl.sh…
echo "Starting download civici Sicilia ......"
sleep 5
./DownloadCiviciByCurl.sh 81008_Erice
./DownloadCiviciByCurl.sh 83040_Limina
./DownloadCiviciByCurl.sh 87001_Aci_Bonaccorsi
......
......
da completare con l’elenco dei comuni ricavato dall’istruzione ogrinfo mostrata in precedenza.
I files .sh sono mantenuti nella cartella “Work”.
Ecco uno snapshot dell’esecuzione di questo primo passo …

Step 2: convertire i dati in formato ESRI shapefile
Il mio obiettivo finale era quello di avere un unico file con tutti gli indirizzi georiferiti disponibili per la Regione Sicilia, e quindi dovevo in un qualche modo unire tra loro, geograficamente, i singoli files GML scaricati.
L’aggregazione geografica di più files GML non sembra sia possibile (dopo una veloce ricerca sul web …), e quindi ho deciso di convertire ogni singolo file GML in uno shapefile per poi unificali tra loro in uno step successivo.
Per eseguire l’operazione di cui sopra ovviamente il tool che meglio si adatta sono ancora le librerie GDAL con il seguente comando ogr2ogr
ogr2ogr -f "ESRI Shapefile" 81008_Erice_4326 CiviciComuniSicilia/GML/81008_Erice_4326.gml
Nel preparare questa trasformazione mi sono accorto che lo shapefile prodotto risultava privo del file di proiezione (.prj), e quindi, con una seconda operazione ogr2ogr ho provveduto ad aggiungere allo shapefile prodotto, il file .prj relativo al sistema di riferimento che volevo utilizzare (EPSG: 4326)
ogr2ogr -a_srs EPSG:4326 CiviciComuniSicilia/Shapefile/NumeriCivici_81008_Erice.shp 81008_Erice_4326/NumeriCivici_81008_Erice.shp
Anche in questo caso ho poi realizzato un programmino shell, denominato ConvertShapefile.sh, reso parametrico ….
echo Convert $1 civici GML into ESRI shapefile .....
ogr2ogr -f "ESRI Shapefile" $1_4326 CiviciComuniSicilia/GML/$1_4326.gml
echo Adding .prj to $1 civici shapefile .....
ogr2ogr -a_srs EPSG:4326 CiviciComuniSicilia/Shapefile/NumeriCivici_%1.shp $1_4326/NumeriCivici_$1.shp
echo Delete temporary files .....
rm -R $1_4326
il quale è poi richiamabile da un programmino di lancio denominato LauncherConvertShapefile.sh …
echo "Starting converting civici Sicilia in shapefiles ......"
./ConvertShapefile.bat 81008_Erice
./ConvertShapefile.bat 83040_Limina
./ConvertShapefile.bat 87001_Aci_Bonaccorsi
......
......
I files .sh sono mantenuti nella cartella “Work”.
Ecco lo snapshot dell’esecuzione di questo secondo passo …

Step 3: creare un unico shapefile di dati
A questo punto non restava che “fondere” insieme i vari shapefile dei singoli comuni in un unico shapefile a livello regionale.
Anche qui viene in aiuto la libreria GDAL con le ogr2ogr che permettono di effettuare questa operazione eseguendo un semplice ciclo: anche in questo caso ho racchiuso il tutto in un programmino shell che ho nominato UnionShapefileComuni.sh
#!/bin/bash
for f in `ls *.shp`
do
echo "Append shapefile " $f " ....."
ogr2ogr -update -append civici_sicilia.shp $f -f "ESRI Shapefile" -nln civici_sicilia
done
Il file .sh è mantenuto nella cartella “Shapefile”.
Ecco uno snapshot dell’esecuzione di questo terzo passo …

Ed ecco che il gioco è fatto, replicabile e, volendo, completamente automatizzabile mettendo i vari passi in un unico shell.
Il risultato è il seguente:
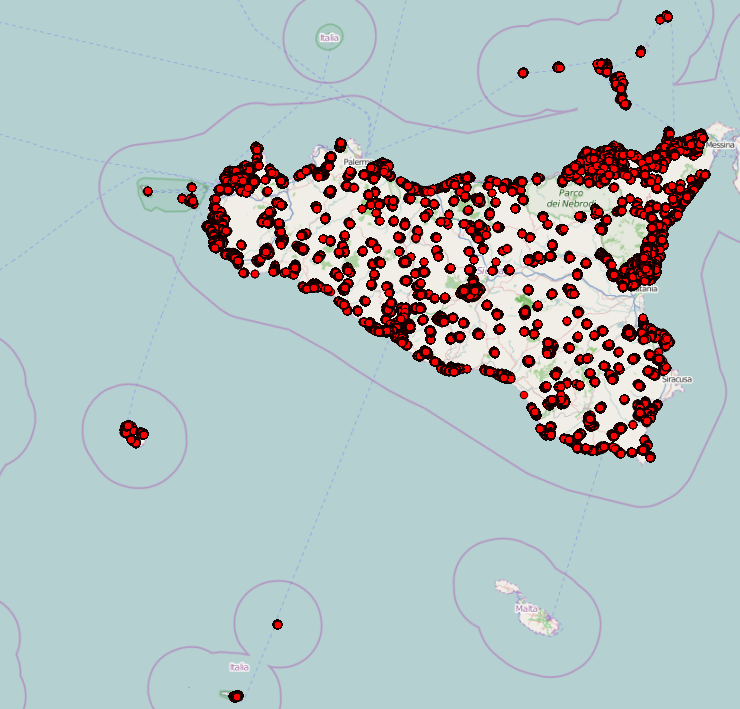

L’intero dataset è scaricabile e disponibile nel rispetto delle licenze originali dei dati di partenza (CC-BY SA).
Come detto in precedenza quello descritto non è l’unico metodo ma ve ne possono essere molti altri, anche più eleganti: ne cito uno, illustrato da Andrea Borruso, che mi sembra di particolare interesse e che si basa sul fatto che i servizi della Regione Sicilia sono contattabili anche via REST, e quindi, partedo da questo, si potrebbe replicare l’esperienza fatta da Maurizio Napolitano nel caso di Regione Umbria.
Un primo utilizzo delle informazioni che ho aggreato? Per visualizzare i dati delle mia raccolta degli indirizzi georiferiti open data in Italia (di cui stò preparando la nuova release … stay tuned!!!): portando i dati su un db POSTGIS e poi usando TileMill ho prodotto i tiles che permettono di visualizzare rapidamente l’intero dataset insieme a tutti gli altri raccolti a livello nazionale.
Spero che queste info possano essere utili.
Numeri civici Open Data in Italia (hashtag #IndirizzatiItalia!): un po’ di dettaglio tecnico
Nel post relativo all’annuncio di Numeri Civici Open Data in Italia (hashtag #IndirizzatiItalia!) non mi sono dilungato nei dettagli tecnici per non appesantire: ora, per chi interessato, fornisco qui alcune informazioni.
Nel documento è possibile trovare, per ogni livello informativo:
- i riferimenti relativi al nome dell’Ente che lo mette a disposizione in modalità open data
- la sua url di pubblicazione
- la sua url di download
- il riferimento della licenza d’uso del dato
- la url di download al dato trasformato in formato ESRI shapefile (senza alterazione della struttura dati), con sistema di riferimento WGS84
I dati sono anche resi consultabili, da un punto di vista geografico, usando il software open source QGIS, in due modalità:
Una breve nota tecnica: è necessario, per la consultazione di livelli informativi del Geoportale Nazionale, che, qualora si operi su una rete locale, si verifichi la corretta configurazione del proxy, e, per rendere operativo lo sfondo OpenStreetMap, che, nel QGIS utilizzato, sia presente ed attivo il plugin OpenLayers. I progetti QGIS sono stati realizzati con la versione 2.0.1 (Dufour).
Per una consultazione web ho invece realizzato un piccolo esempio in web mapping basato su HTML, Javascript e Leaflet.
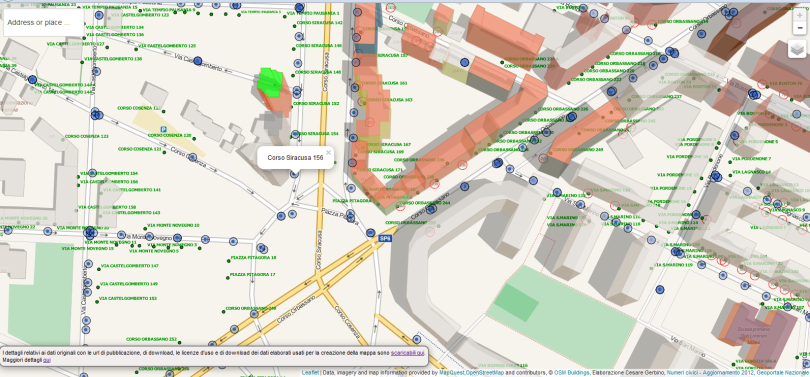
L’applicazione permette di:
- localizzare l’area di interesse per indirizzo o nome della località
- attivare / disattivare i layer di interesse (il dettaglio dell’indirizzo <via> <civico> è fornito solo alle scale di maggior dettaglio)
- interrogare interattivamente il livello informativo “Civici Geoportale Nazionale – (WFS)”
Visto che nell’applicazione di web mapping non era possibile elencare i più di 100 livelli informativi, questi sono stati raggruppati per Regione e/o Ente realizzando per ognuno di essi un singolo catalogo raster TMS usando come soluzione TileMill.
Per rendere più veloce la produzione dei vari cataloghi i dati, dopo essere stati trasformati in formato ESRI Shapefile e riportati in WGS84 (EPSG 4326), sono stati caricati in POSTGIS.
Sono anche disponibili due livelli informativi tratti dai geoservizi OGC offerti dal Geoportale Nazionale, il servizio WMS dei civici aggiornamento 2012 e il corrispettivo servizio WFS che permette l’interrogazione interattiva dei singoli numeri civici (funzionalità disponibile solo alle scale di maggior dettaglio onde evitare, da un lato, di richiedere un numero di features eccessivo al server del Geoportale Nazionale, e dall’altro di appesantire la fase di rendering sul browser).
Ovviamente sono disponibili diversi livelli informativi di sfondo (baselayer).
La modalità di pubblicazione in web mapping adottata, sebbene funzionale, ha il vantaggio di essere semplice e non richiede particolari necessità infrastrututrali, è sufficente un web server e un po’ di spazio disco. Al tempo stesso ha, indubbiamente dei limiti, il primo tra tutti è che la sua “semplicità” porta a perdere il livello di dettaglio dei dati raccolti, rendendoli disponibili solo in forma aggregata e come cataloghi raster TMS.
Una soluzione più “enterprise” richiede una disponibilità di un minimo di infrastruttura che al momento non ho adottato non disponendone. Non per questo non ho individuato una possibile soluzione che permetta, da un lato, di mantenere il dettaglio del dato e al tempo stesso permetta di garantire sia buone prestazioni in consultazione sia l’interoperabilità.
Tale soluzione è basata su una pila tecnologica completamente open source (quindi facilmente replicabile da chi interessato …), che comprende:
- data base: POSTGIS
- application server GIS: GEOSERVER
- web gis viewer: GeoExplorer
Questa rappresenta “una” scelta, non l’unica adottabile nel panorama del mondo gis open source come pure nell’ambito del mondo gis bastao su soluzioni proprietarie.
Implementativamente e per ragioni di praticità, ho utilizzato OpenGeoSuite 4.0.2 (usando una installazione di default, senza alcun parametro di ottimizzazione …), su un quadcore Intel con 8Gbyte di RAM e Windows 7 Enterprise: ovviamente questa non è da considerarsi una configurazione adatta per un ipotetico ambiente di produzione.
Mentre la scelta di POSTGIS come data base spaziale direi che è quasi “inequivocabile”, la scelta di GeoServer è stata indirizzata dal fatto che, oltre ad essere un ottimo gis server, ha una caratteristica che, nel caso specifico dei dati che si dovevano trattare, tornava molto utile, vale a dire la capacità di implementare un point clustering server side per facilitare la consultazione di layer con un gran numero di punti che, altrimenti, dovrebbero essere renderizzati sul client, con prestazioni non accettabili.
Il tutto, come valore aggiunto, realizzato usando modalità standard, vale a dire uno stile SLD, ed esponendo il layer in interoperabilità secondo i consueti standard OGC (WMS e WFS).
NOTA: l’esempio di stile SLD fornito dal tutorial Buondless non permette di interrogare i singoli punti e quindi ho dovuto leggermente modificarlo e lo rendo liberamente scaricabile.
Volendo approfondire questa funzionalità ho quindi adottato questa soluzione.
Ecco un video in cui, usando GeoExplorer (integrato in OpenGeoSuite …), è possibile consultare tutti i 149 layer messi a disposizione
mentre ecco un video in cui, alcuni dei layer dei civici puntuali sono consultati come layer WMS da un client QGIS
dimostrando quindi come, se ce ne fosse ancora bisogno, grazie all’adozione di servizi GIS esposti secondo standard di interoperabilità e con architetture in grado di scalare opportunamente sia possibile offrire dati geografici a diversi fruitori, sia gis desktop (commerciali e non), sia web browser (usando librerie open source quali OpenLayers, Leaflet, ecc .. , ma anche usando soluzioni commerciali), sia mobile, ma a questo punto diventa un puro esercizio informatico che non ha grande valore aggiunto quindi mi fermo qui.
GIS in the Cloud: CartoDB
Tempo fa ho pubblicato un post di approfondimento su MapBox come prima soluzione di GIS in the cloud analizzata.
Eccomi ora alla seconda puntata che è imperniata su CartoDB.
Riprendendo quanto riportato sul sito “ … CartoDB is a geospatial database on the cloud that allows for the storage and visualization of data on the web …. “: analogamente a MapBox quindi il suo core business è quindi quello di permettere di realizzare facilmente la pubblicazione dei propri dati georiferiti in mappe su sfondi predefiniti e personalizzabili, anche se, come potremo vedere, si differenzia da MapBox stesso in alcuni aspetti.
Per utilizzare l’interfaccia grafica di pubblicazione dei dati è necessario registrarsi sul sito. Effettuato il login l’utente ha a disposizione, nella versione free of charge, lo spazio virtuale per creare / effettuare l’upload sino a 5 tabelle, per un massimo di 5 Mbytes: le tabelle, che rappresentano i layers, possono poi essere visualizzate composte in “visualizzazioni” che sono quindi mappe tematiche sovrapposte ad uno sfondo cartografico di riferimento.
Per esigenze superiori sono offerte diverse modalità di sottoscrizione del servizio a pagamento.
E’ possibile creare tabelle da zero o effettuare l’upload di dati già in possesso secondo diverse modalità:
- usando dati disponibili localmente o fornendo la URL di accesso
- usando dati caricati su Google Drive
- usando dati caricati su Dropbox
CartoDB per i propri tutorial mette a disposizione una serie di dati campione.
I formati supportati sono i seguenti:
- .CSV .TAB * Comma-separated values and Tab delimited file
- .SHP ** ESRI shapefiles
- .KML, .KMZ Google Earth format
- .XLS, .XLSX *** Excel Spreadsheet
- .GEOJSON GeoJSON
- .GPX GPS eXchange Format
- .OSM, .BZ2 Open Street Map dump
- .ODS OpenDocument Spreadsheet
- .SQL Experimental SQL format dumped from CartoDB
CartoDB suggerisce di fare l’upload dei dati sempre in modalità compressa (zipfiles).

Per ogni tabella l’utente ha a disposizione due modalità di visualizzazione, quella tipica di un foglio elettronico e quella su mappa: ogni modalità di visualizzazione mette a disposizione dell’utente una toolbar (alla destra della tabella / mappa), con alcune funzionalità.


La visualizzazione a foglio elettronico permette di:
- impostare query sql
- impostare filtri
- fare merge di tabelle
- aggiungere colonne
- aggiungere righe
La visualizzazione a mappa permette di:
- impostare query sql
- impostare filtri
- impostare la modalità di tematizzazione
- definire lo stile di rappresentazione (CartoCSS)
- definire quali attributi visualizzare in seguito all’azione di identify sulle features
- definire la legenda
- aggiungere features
- impostare la mappa di sfondo
A livello di rappresentazione su mappa lo strumento offre delle modalità di default ma l’utente può utilizzare, per rappresentazioni più complesse e complete, un linguaggio CSS-like denominato CartoCSS che permette un maggiore dinamismo come ad esempio usare parametri condizionali che combinati con il potere degli statements SQL permettono visualizzazioni molto avanzate
Altra funzionalità molto potente è quella che permette di fare merge di tabelle (Regular join), tra loro sulla base di un campo comune. Sono previste, al momento non ancora disponibili, anche funzionalità di merge spaziale (Spatial merge), ad esempio point in polygon in cui sarà poi possibile associare criteri quali SUM, COUNT, AVERAGE, ecc …
Come detto in precedenza per pubblicare più layers occorre creare una visualizzazione.

Questa può poi essere personalizzata, pubblicata, condivisa o acceduta via API.
Entrando un po’ più nel dettaglio i punti di forza di CartoDB sono i seguenti:
Analisi dei dati
Per mantenere i dati che gli utenti caricano sul cloud CartoDB si basa su POSTGRESQL e POSTGIS (a cui si rimanda per i dettagli tecnici) come data base. Per quello che riguarda la componente spaziale il data base non solo offre il completo controllo dei dati (insert, update e delete), ma mette anche a disposizione una suite di funzionalità e tools molto potenti per analizzare i dati stessi.
Sviluppo di applicazioni
CartoDB non mette a disposizione dell’utente finale un’interfaccia grafica di pubblicazione dei dati attraverso una mappa come visto in precedenza, ma offre anche:
- un potente backend per il data management e l’analisi geospaziale, offrendo agli sviluppatori un’API di programmazione javascript per la realizzazione di mappe interattive da integrare all’interno di soluzioni web realizzate con linguaggi di programmazione diversi
- una SQL API che permette di interrogare i dati ma anche, attraverso connessioni sicure (API keys o autenticazioni Oauth), di compiere operazioni di scrittura su dati stessi
Sicurezza sui dati
CartoDB offre, qualunque sia la sottoscrizione del tipo di livello di hosting della piattaforma, un elevato livello di sicurezza sui dati, permettendo di ospitare tabelle private a cui è possibile accedere con meccanismi di sicurezza
Scalabilità della soluzione
Le mappe create con CartoDB sono distribuite su una rete mondiale attraverso tecnologia CDN. Questo assicura la massima affidabilità e velocità quando si debbano trattare grandi quantità di richieste. La scalabilità viene anche offerta a livello di data storage permettendo di effettuare upgrade del proprio account in qualunque momento.
Open Source
CartoDB è stato costruito su uno stack di diverse tecnologie open source che includono POSTGRESQL, POSTGIS, Mapnik e WindShaft.
Tutto in codice di CartoDB è disponibile su GitHub: questo permette potenzialmente a chiunque di potersi replicare il locale la soluzione nella sua interezza.
Di particolare interesse in questa soluzione sono i tutorials e i video messi a disposizione seguendo i quali è possibile, in modalità molto semplice, produrre mappe evolute sia in termini di rappresentazione sia in termini di funzionalità utente.
Ecco i riferimenti:
Ed ecco alcuni di quelli che ho trovato più interessanti:
Come aggiungere la mappa di OSM come sfondo
[vimeo http://vimeo.com/79772252 w=500&h=281]
Non è così immediato o facilmente documentato, ma è spiegato chiaramente in questo video
Mappare dati excel
[vimeo http://vimeo.com/77289264 w=500&h=281]
Utilizzo Torque
[vimeo http://vimeo.com/79115503 w=500&h=281]
Illustra come sia immediato visualizzare come una grandezza spaziale cambia nel tempo.
Come visualizzare l’editing nel tempo dei contributi OSM nelle Filippine
[vimeo http://vimeo.com/79199985 w=500&h=281]
Interessante come sincronizzare lo shapefile messo a disposizione in rete su GeoFabrick.
Creare una tabella sincronizzata.
[vimeo http://vimeo.com/78298157 w=500&h=281]
Interessante per realizzare una mappa del meteo in tempo “quasi reale” magari sfruttando dai open disponibili. Funzionalità a pagamento dal piano di sottoscrizione da 49$/mese
Visualizzazione sincronizzata di tabella da Dropbox. Funzionalità a pagamento dal piano da 49$/mese
[vimeo http://vimeo.com/78297755 w=500&h=281]
Funzionalità a pagamento dal piano da 49$/mese
POSTGIS: un workshop online per imparare ad usarlo
Un workshop online per imparare ad usare POSTGIS passo passo.
Il workshop usa OpenGeo Suite ed è corredato da un bundle di dati.
E’ licenziato come Creative Commons share alike with attribution, ed è liberamente ridistribuibile rispettando i temini di tale licenza.
Ottima iniziativa per chi ci vuole avvicinare a POSTGIS.
OpenGeo investe nella comunità QGIS
Sul blog di OpenGeo oggi è apparso un post che annuncia l’interesse di OpenGeo nell’investire in QGIS desktop.
La notizia ha una certa rilevanza visto che OpenGeo sinora si è storicamente concentrata sulle componenti server enterprise: la sua OpenGeo Suite che si basa infatti sulla OpenGeo Architecture costituita da PostGIS, GeoServer, GeoWebCache, OpenLayers e GeoExt.
In questo scenario mancava una soluzione GIS Desktop matura che permettesse di completare la suite e la scelta sembra essere caduta su QGIS che sicuramente è il tool GIS Desktop open source più ampiamente diffuso ed utilizzato, con una nutrita e quanto mai vivace comunità e che si appresta a rilasciare la release 2.0.
Questa notizia potrebbe rivelarsi una svolta importante nel panorama delle soluzioni GIS open source visto che nell’offerta di OpenGeo si va a completare un tassello sinora non integrato.
Le potenzialità sono molte e tutte decisamente interessanti:
- integrazione di QGIS nella OpenGeoSuite diventando uno strumento non solo per fare gis desktop ma anche un modo per fare configurazione della suite stessa: gli utenti della suite potranno quindi prossimamente creare, analizzare, pubblicare e consumare dati e servizi geospaziali
- integrazione di QGIS con GeoGit, la soluzione per il versionamento dell’informazione spaziale su sui OpenGeo sta lavorando. Gli utenti desktop saranno in grado di lavorare su dati geospaziali in ambienti distribuiti o parzialmente disconnessi. Il client GeoGit in QGIS permetterà non solo agli utenti di gestire i loro repository e quindi le proprie versioni, ma anche di avere a disposizione l’intero contesto di QGIS, rendendo GeoGit un altro data source dentro QGIS, esattamente come ogni altro database o servizio OGC
Si prospettano quindi orizzonti interessanti per il GIS open source: attendiamo impazienti e fiduciosi!
Fonte: OpenGeo Blog
Sinergia tra province olandesi su soluzione GIS open source permette di risparmiare 4.5 milioni di Euro
Nella recente INSPIRE Conference tenutasi a Firenze dal 23 al 27 Giugno, tra i vari interventi presentati, uno in particolare ha messo in evidenza come un’azione sinergica di 12 province olandesi che hanno collaborato congiuntamente allo sviluppo di una soluzione basata su prodotti open source, ha permesso, dal 2009 ad oggi, un risparmio considerevole di costi quantificato in ben 4.5 milioni di Euro.
Nel 2006 infatti le 12 province olandesi hanno congiuntamente sviluppato una soluzione per la gestione e visualizzazione di dati geografici denominata Flamingo, un geo-cms basato su prodotti open source e a sua volta rilasciata in modalità open source (licenza GPL2).
Ecco un video (in olandese …..), di presentazione
Di recente le 12 province hanno creato una fondazione per supportare la comunità degli utenti di Flamingo con l’intenzione di estendere la comunità degli utenti della soluzione anche al dià dei confini olandesi.
Come detto in precedenza l’esperienza si è rivelata positiva permettendo un sensibile risparmio tanto che verrà replicata con le medesime modalità per andare a realizzare un secondo tool denonimato CDS (Central Data and Service environment), il cui obiettivo sarà quello di importare le informazioni geografiche delle singole province, validarle e renderle disponibili come national dataset, seguendo le direttive INSPIRE.
La soluzione sarà realizzata “on top” a prodotti open source quali ad esempio PostGIS e Deegree, che sono supportati dalla Open Source Geospatial Foundation (OSGEO).
Al netto degli aspetti tecnici di cui riferisco più avanti, l’iniziativa delle province olandesi è significativa e dimostra come l’essere capaci di fare sinergia tra enti della P.A di un Paese permette di portare risultati da un punto di vista economico, concreti.
Questo dovrebbe far riflettere: quanti progetti “simili” (es. quanti geoportali, quanti web gis viewer, ecc ..), sono stati, e vengono ancora, oggi proposti dagli Enti della P.A in termini di ricerca di finanziamenti, sia a livello nazionale sia a livello comunitario? Una capacità progettuale d’insieme tra gli enti, in sinergia tra di loro, che permetta di creare una “massa critica” tale da andare a cercare insieme finanziamenti significativi, più facili forse da ottenere che non con iniziative più piccole, molto simili tra di loro, non permetterebbe forse di fare maggiore efficienza e di spendere meglio soldi che sono un po di tutti noi? Il modello olandese presentato sembra confermare questa sensazione.
Purtroppo, e sarebbe stato interessante, non è così facile trovare dettagli tecnici sulla soluzione Flamingo visto che buona parte dei siti di riferimento sono in olandese e anche sui sito ufficiale della soluzione non sono così evidenti questi dettagli (o almeno io non sono stato in grado di trovarli ….), e questo per una soluzione proposta a riuso non è bellissimo.
Altro aspetto se vogliamo critico da un punto di vista tecnico, è la decisione di implementare, per quanto basato su prodotti open source e rilasciato a sua volta in modalità open source, un nuovo (ennesimo …)?, geo-cms, framework o similare: forse, una volta fatta la scelta dell’open source, sarebbe stata necessaria una valutazione se non fosse stato più opportuno “investire” nell’evoluzione di un qualcosa di già disponibile della comunità GIS open source, e non credo che sarebbe mancato materiale su cui fare dei ragionamenti.
Forse l’iniziativa olandese sarebbe stata ancora più interessante!
Fonte: Between the Poles
Mappa del Trentino: un esempio di un uso sinergico di dati open
E’ stata pubblicata la mappa web e mobile della Provincia Autonoma di Trento da parte di WebMapp.

Si tratta di un bell’esempio di come si possano ottenere eccelenti risultati utilizzando dati e tools open source.
I tre organismi produttori dei principali dati utilizzati per costruire la carta sono infatti:
- OpenStreetMap per i dati relativi al caseggiato e alla rete dei trasporti
- OPENdata Trentino per i dati altimetrici, uso del suolo, toponomastica, idrografia e piste ciclabili
- Società degli Alpinisti Tridentini (SAT) per la rete dei sentieri
I software opensource utilizzati sono stati:
- PostGis e Quantum Gis per leggere, editare, convertire i dati geografici
- Tilemill per il rendering cartografico
- Leafletjs per pubblicare la mappa sul web
La mappa delle Trentino è distribuita con licenza Creative Commons Attribuzione-Non commerciale-Condividi allo stesso modo 3.0 Italia
Ottima iniziativa e bell’esempio da seguire!
GeoGit: un nuovo tool (in alpha version), offerto da OpenGeo
Ho già citato in un precedente post l’esperienza della città di Chicago che, per condividere i propri dati con gli utenti ha pubblicato alcuni dei suoi open data georiferiti su GitHub sollecitandone i fork per gli aggiornamenti,
Ora è stato recentemente annunciato da OpenGeo un nuovo prodotto open source, rilasciato in alpha version, denominato GeoGit che ha come obiettivo (cito testualmente …), “…. to propose a new approach to working with spatial data, recommending a shift from treating spatial data simply as data to considering it as programmers do source code.”
Altra frase che ha suscitato il mio interesse è la seguente: “ …. We propose that organizations can benefit from crowdsourcing spatial data while retaining control over their information repositories and maintaining authoritative data sources.”
I principi su cui si basa questa iniziativa sono stati enunciati in tre white papers di cui riporto i riferimenti:
- Distributed Versioning for GeoSpatial Data (Part 1)
- Distributed Versioning for GeoSpatial Data (Part 2)
- Distributed Versioning for GeoSpatial Data (Part 3)
Provo a riassumere nel seguito quanto descritto nel dettaglio nei tre papers di cui sopra di cui consiglio la lettura e a cui comunque rimando.
La sfida che viene proposta è sicuramente innovativa, quanto mai impegnativa ma al tempo stesso molto affascinante: provare ad affontare il tema della creazione e gestione dei dati geografici con gli stessi principi collaborativi con cui viene trattata la gestione del codice sorgente.
Questo offre prospettive interessanti come pure l’obiettivo dichiarato di ridurre il tempo dedicato alla gestione del dato stesso per andare ad aumentare il tempo dedicato a creare valore aggiunto (funzionalità e servizi), su di esso
L’idea non è completamente nuova: alcuni tentativi di introdurre un sistema distribuito di controllo di versione sui dati geografici è già stato affrontato nel tempo da ESRI con ArcSDE e dalla stessa ORACLE con Workspace Manager.
Lo stesso progetto OpenStreetMap offre un sistema di versionamento, per quanto intorno ad un unico database centralizzato.
L’idea che guida OpenGeo nell’adattare i concetti chiave del versionamento distribuito tipico del mondo software ai dati spaziali, si basa su una similitudine che è la seguente: molte persone che usano il software non sono interessate ad ottenere accesso o avere maggiore conoscenza sul codice sorgente, analogamente a come molte persone che usano le mappe non sono interssate ai dati su cui queste di basano.
Al tempo stesso come gli sviluppatori possono essere interessati al codice sorgente di un’applicazione per poterlo modifcare, correggere. migliorare, coloro che sono interessati ai dati spaziali possono avere interesse nel modificarli, correggerli e migliorarli.
OpenGeo auspica che, analogamente a come è avvenuto nel mondo del software, dove questo approccio di condivisione ha portato ad una maggiore diffusione e consapevolezza unita ad un aumento della qualità del software, lo stesso avvenga nel mondo dei dati spaziali.
Quanto proposto da OpenGeo sembra andare oltre il modello impostato e portato avanti con successo da un progetto importante come OpenStreetMap il cui obiettivo è quello di raccogliere, e ridistribuire a tutti, in un’unica banca dati le informazioni spaziali attraverso le operazioni di edit fatte da un numero di crowdmapper volontari e appassionati sempre maggiore: si propone un modello collaborativo che richiede un nuovo paradigma e nuove problematiche da dover affrontare.
Un approccio che porti ad un modello collaborativo basato su un modello di versionig distribuito sui dati dovrebbe facilitare la collaborazione tra diverse organizzazioni / enti che hanno necessità di utilizzare e gestire i medesimi livelli informativi.
Ad oggi queste esigenze, per quanto le diverse iniziative / strumenti / tools che gravitano intorno ai concetti di Spatial Data Infrastructure (SDI), in senso lato, cerchino di mitigare la duplicazione di dati, non hanno ancora avuto una risposta esaustiva e resta sempre necessaria un’autorità centrale che si faccia carico di integrare (con diversi livelli di possible automatismo ma pur sempre con un elevato grado di controllo umano), le diverse sorgenti di informazione.
Un modello di versionig distribuito sui dati potrebbe semplificare la collaborazione, in quanto ogni organizzazione /ente manterrebbe il controllo completo sulla propria copia dei dati (potendovi applicare i propri processi di quality assurance), e non cedere così il controllo ad un’autorità esterna, ma al tempo stesso avrebbe visione di ogni change presenti su ogni repository delle altre organizzazioni e decidere se e quando effettuare i merge (per chi interessato nell’articolo originale viene riportato un esempio di dettaglio).
Il modello proposto potrebbe essere anche strumento abilitante per permettere un colloquio fattivo tra due mondi che ad oggi proseguono il loro cammino parallelamente guardandosi a distanza: il mondo dei dati geografici “ufficiali” o certificati (authoritative), generalmente gestiti da organizzazioni governative in grado di certificare le proprie informaizoni, ed il mondo della neo-geografia o del Volunteered Geographic Information (VGI) in cui rientrano tutti gli utenti crowdsourced legati a realtà quali OpenStreetMap, Google MapMaker, Ushahidi, ecc … .
I due mondi hanno ovviamente cicli di vita applicati ai dati completamente diversi: l’approccio VGI basato sul crowdsourcing permette a chiuque di fare edit dei dati, permettendo così si avere dati più aggiornati per quanto potenzialmente (????!!!!), passibili di errori, mentre l’approccio “authoritative” permette un modello centralizzato in cui il dato viene aggiornato e alterato in modo controllato, permettendo un dato di maggiore precisione (????!!!!), ma inevitabilmente con tempi più lenti.
Con un modello di versioning distribuito sui dati le organizzazioni / enti ufficiali potrebbero disporre del meglio di entrambi.
Infatti se da un lato con lo stesso approccio potrebbero collaborare con altre organizzazioni / enti come descritto in precedenza, dall’altro potrebbero anche collaborare con singoli o gruppi interessati a vario titolo al miglioramento del dato stesso.
Il fornitore del dato può continuare a pubblicare versioni dei dati pienamente testati e verificati con un ciclo di vita del dato più “lento” per chi interessato a questa tipologia di dato, mentre chi usa il dato e ha necessità di avere un livello informativo più generale ed aggiornato, anche a scapito della sua certificazione, può mantenere una copia del dato certificato su cui fare le proprie modifiche / aggiornamenti e periodicamente riportarle sul repository del dato “authoritative” da cui questi poi rientreranno nel ciclo di vita del dato ufficiale (anche qui per chi interessato nell’articolo originale viene riportato un esempio di dettaglio).
Un modello di versioning distribuito sui dati avrebbe vantaggi anche nel caso di utilizzo di strumenti portabili di acquisizione di dati sul campo dove spesso non è garantita la copertura di rete o la sua affidabilità. In questo caso infatti il dispositivo mobile potrebbe essere visto come l’ennesimo repository da sincronizzare verso la base dati centrale o master.
A livello di rete questo tipo di approccio potrebbe trovare ulteriori vantaggi se si considera che il traffico potrebbe essere limitato rispetto ad una situazione tradizionale di upload / download in quanto sarebbero interessate solo le features create / modificate e non l’intero livello informativo.
Alcuni vantaggi, non molto in realtà se confrontato all’effettiva necessità ed onere, si potrebbero avere anche a livello di metadati in quanto gli strumenti di controllo di versione raccolgono metadati automaticamente, alcuni dei quali potrebbero essere utilizzati per tracciare la storia di ogni dataset per conoscere chi ha modificato cosa quando.
OpenGeo, dopo aver valutato diverse alternative, ha infine scelto di prendere in prestito le idee migliori da un software, non-geospaziale, di versioning distribuito come Git e di costruire qualcosa di nuovo che fosse in grado di gestire dati geospaziali.
Si tratta di un primo passo ma altri possibili sono previsti come possibili alternative / evoluzioni:
- usare un approccio “ibrido” introducendo un database spaziale per fornire acecsso rapido e indicizzazione spaziale ai dati lasciando a Git le parti di versioning e history
- usare la tecnologia che sta alla base di CouchDB. Questo approccio permette di seperare il back end ed il front end così che se qualche novità interessante si presentasse sul mondo degli strumenti open source sia possibile e facilitato il suo utilizzo
GeoGit non è direttamente compatibile con Git o GitHub ma adatta i concetti di base di Git al contesto dei dati spaziali e si basa sia su GeoSynchronization Service module (una specifica OGC sulla sincronizzazione dei dati), sia sugli standard del Web Feature Service 2.0 (WFS-T). Le features sono implementate usando il formato binario Hessian e il formato Well Known Binary (WKB), standard OGC che è ampiamente supportato da diversi tool ( per chi interessato nell’articolo originale viene riportato un esempio di dettaglio).
Ovviamente ci sono diversi punti ancora aperti: editando direttamente un datastore POSTGIS con un qualunque client gis desktop senza passare attraverso GeoGit si creano situazioni di inconsistenza, in modo del tutto analogo a come avverebbe se, in un utilizzo tradizionale di GitHub, si facessero accessi diretti sul repository remoto senza fare il push delle modifiche sul repository locale.
Ovviamente per permettere di poter lavorare in una situazione “mista” in cui si possano fare editing sia in modo tradizionale sia attraverso l’utilizzo di WFS-T sarebbe necessario implementare delle strategie di notifiche sul repository attraverso trigger a livello del db POSTGIS oppure con plugin specifici sui vari client, quindi un mondo ancora piuttosto complesso.
Altri limiti attuali sono:
- è possibile utilizzare repositories con versioni lineari quindi non ci sono possibilità di fare branch, diff o rollbacks
- è stato testato su POSTGIS ma è stato progettato per lavorare con qualunque datastore che possa restituire degli ID stabili e quindi dovrebbe lavorare con ORACLE, ArcSDE, SQL Server e DB2
Al netto di queste limitazioni e come detto in precedenza il prodotto è disponibile nella sua alpha version.
Proseguono le attività tra cui:
- un’interfaccia javascript based realizzata sulla base di GXP così da essere facilmente incorporata in GeoExplorer, GeoNode e altre applicazioni che permetta di avere un’applicazione demo di front end così da interagire con la componente di back end
- uno strato di API javascript che permetta funzionalità di “diff”, “rollbacks” ma anche visualizzare l’history, fare confronti tra versioni sia sui dati spaziali sia sui dati associati. Questa fase è considerata molto complicata in quanto si tratta di andare ad affrontare concetti completamente nuovi se applicati ad un contesto geospaziale: quali sono i significati di un “diff”, un “merge” o un “clone” nel contesto del versionamento distribuito di dati spaziali?
- integrazione in GeoNode
- integrazioni sia nel mondo Mobile sia nel mondo Desktop. In particolare per quest’ultimo aspetto c’è da considerare la proliferazione di strumenti sia open source sia proprietari
In conclusione quindi GeoGit si presenta come soluzione tutt’altro che matura, anzi, nella versione attuale decisamente limitata, ma indubbiamente si tratta di un progetto interessante da seguire nelle sue evoluzioni.
Fonte: Blog OpenGeo
Where Camp EU 2013: alcune note
Dal 18 al 19 Gennaio 2013 si è tenuto a Roma Where Camp 2013 presso Porta Futuro: riporto alune note della mia partecipazione che non saranno esaustive di tutti gli interventi ciò dovuto al fatto che il mio inglese è … diciamo …. un po “fuori allenamento”.
I partecipanti non erano moltissimi, orientivamemte tra i 30 e i 40: diciamo che Gennaio forse non è il periodo migliore per questi incontri e comunque la crisi si fa un po sentire per tutti. Ovviamente più nutrita la pattuglia italiana ma comunque discreta anche la presenza straniera
L’evento si è aperto con una presentazione di di Mark Killiffe sull’utilizzo di OSM in ambito umanitario in Africa, per mappare in zone degradate la presenza ad esempio di toilette: può sembrare a prima vista una cosa banale ed inutile ma occorre considerare che 3.41 milioni di persone all’anno muoiono per scarsa igiene dell’acqua. Non basta tuttavia mappare i punti ma occorre coinvolgere la popolazione per mantenere “vivo” il dato (situazioni di degrado e contaminazione, nuove toilette legate all’aumento delle popolazione, ecc ….).
Il dato deve essere pubblico e open e da qui l’uso di OSM: è stata realizzata una piattaforma open source denominata Taarifa
Altra presentazione è stata su CartoDB (Sandro Santilli). E’ stato fatto un esempio di utilizzo usando query spaziali su POSTGIS (una delle caratteristiche principali del prodotto), dopo aver caricato su POSTGIS i dati open data degli hotspots wi-fi: ad esempio i punti che ricadono nei dintorni di Porta Futuro, o quelli che ricadono dentro le aree verdi, ecc .. ), con anche tematizzazioni sui risultati ottenuti, esmepio tematizzare diversamemnte gli hotspots trovati sulla base della loro tipologie o le aree verdi sulla base del numero di hotspots che vi ricadono dentro.
Tutto quanto è stato fatto facendo dei filtri spaziali sul layer POSTGIS: molto potente da questo punto di vista anche se serve comunque una buona dose di conoscenza tecnica (le query spaziali non sono proprio alla portata di un utente entry-level ….) da parte di chi usa il back end.
Altra cosa interessante è che è open source (licenza BSD), e quindi ognuno se lo può installare sui propri server.
Francesco Stompanato ha presentato una soluzione mobile per raccolta dati in ambito World Food Programme (WFP): dopo alcuni approfondimenti la scelta è caduta su Open Data Kit.
E’ stata poi la volta di Paolo Corti fare una presentazione di GeoNode. Il prodotto di basa su Django, GeoServer e POSTGIS come tecnologie di base. Ad oggi permette di fare upload di shapefile (occorre caricare i singoli file, altre soluzioni “concorrenti” permettono di caricare lo zip dello shapefile che forse è più comodo ….), e GeoTiff in futuro sono previsti altri formati. L’upload dello shapefile crea un layer POSTGIS e successivamente si possono caricare i metadati (ad oggi mi sembra di aver capito che si basa su GeoNetwork ma forse è in corso un’attività per usare pyCSW ….).
Il backoffice per fare authoring della mappa si basa su GeoExplorer di OpenGeo: è possibile fare anche editing dei dati via web.
E’ previsto il supporto di WMS esterni.
Il prodotto è open source e si può quindi scaricare da GitHub.: tra qualche mese dovrebbe essere rilasciata una nuova versione
E’ stata poi la volta di Michael Gould dell’ESRI Educational Community (da qualche anno in ESRI ma con un passato nel mondo GIS Open ….), che ha parlato a braccio di ciò che è ESRI, coma lavora, come si relaziona con il mondo Open Source ecc … Molte delle cose riportate erano notizie che chi segue un po’ i vari post sulle rete forse conosceva già (GeoPortal come prodotto open source, le estensioni di ArcGIS Dekstop per fare editing su OSM, ArcGIS Desktop Home Edition a soli 100 $ annnui, le recenti acquisizioni di GeoIQ e di Geoloqui, ecc … ), ma sentirli riassunti dalla viva voce di un autorevole esponente ESRI è stato comunque interessante. La notizia più “curiosa” è stata quella che ESRI paga i propri dipendenti su base oraria “anche quando sono fuori ufficio” (sostanzialmente si fidano della professionalità dei dipendenti ….): un modo un po inusuale di lavorare anche se immagino comunque per obiettivi.
Bert Spaan di Waag Society ha tenuto invece un intervemto su CitySDK Mobility, un progetto che ha visto coinvolti diversi partners europei (Amsterdam, Roma, Helsinky, Lamia, Lisbona, Istanbul, Manchester e Barcellona), in un contesto di smart city per la partecipazione e la mobilità.
L’obiettivo è quello di pubblicare dati per la mobilità come open data e fornire delle API specifiche per il loro utilizzo (trasporto e traffico). Tutti i dati possiedono una proprietà (location), e sono strutturati ed esposti in modo multiplo (excel, csv, shapefile, drf, ecc …). La localizzazione è si importante ma è un attributo (comune), a tutti gli “oggetti” e il progetto mette enfasi sugli oggetti, ognuno dei quali ovviamente avrà attributi descrittivi diversi
Il concetto di “mobilità” è, nel contesto del progetto, parecchio allargato perchè tratta le informazioni sui mezzi pubblici, le mappe, gli orari. il meteo, le informazioni in tempo reale sul traffico, sino ad arriavre ad includere le informazioni crowdsourced.
Il progetto utilizza OSM sfruttando i livelli informativi di interesse: strade, ferrovie, fermate autobus, metro, ecc .. e supporta standard quali GTFS.
Altre presentazioni:
- Topologia in PostGIS 2.0 (Sandro Santilli): introduzione alla topologia in POSTGIS 2.0 con un po di storia, cos’è la topologia, il modello concettuale
- R: software per statistica molto potente e con una integrazione anche con le parti spaziali e di mappa
- OSGeo Live (Luca Delucchi)
La prima giornata si è poi chiusa con un ampio dibattito a ruota libera su OSM e il suo futuro: qualità del dato, rinnovamento e differenziazione del sito (utente finale, mappatori, sviluppatori, ecc .. hanno esigenze diverse e ad oggi c’è un solo sitoe tutti si atterra lì), modelli di business (fare o meno una sorta di OMS Premium con dati di maggiore qualità/ certificazione? Chi lo fa?), ecc …
Il secondo giorno (con un po di defezioni ….) si è aperto con GeoAvalanche (Francesco Bartoli), una soluzione open source (GNU GPL v3), per raccogliere informazioni georiferite sulle valanghe. La soluzione è basata su una personalizzazione di Ushahidi e ha una componente server basata su GeoServer.
Si è proseguito con una anticipazione di quello che sarà GRASS 7 (Luca Delucchi). Lo sviluppo è iniziato nel 2008 con un gruppo di core developeers di 7-8 persone.
Dovrebbe essere rilasciato nel 2013 anche se non esiste ancora una data e una schedulazione, e comunque scaricabile e disponibile per test su Linux, Windows e MacOS
Drasticamente restrutturato: eliminato codice non utilizzato, miglioramenti e bug fixing, new features. Ecco un breve elenco di alcune caratteristiche:
- eliminato Tcl/Tk GUI e sostituito ocn wxPython GUI
- migliorata la parte sui dati vettoriali
- migliorata la parte di scripting Python
- librerie 3D raster
- SQLite è il sistema di default come libreria db (no supporto parti spaziali per ora solo alfanumerici)
- POSTGIS connection diretta per editing
- supporto temporal GIS
- supporto WPS: è possibile esporre processi in GRASS così che questi possano essere agganciati da motori WPS (es, PyWPS)
- GUI; map swipe
- GUI: animation
- Python: semplifica la programmazione e l’uso dei comandi
- GUI: semplifica la user experience e l’uso dello strumento
L’ultimo intervento a cui ho assistito prima di lasciare il camp è stato quello di Laurence Penny che ha illustrato l’evoluzione delle mappe stradali / turistiche sin dai primordi passando per gli antichi romani, il medioevo, e pian piano sino ai giorni nostri. E’ stato possibile vedere anche alcuni esempi reali con guide turistiche di fine ‘700 o ‘800 scoprendo così che cose che ad oggi affascinano quali Street View o i navigatori per auto in realtà erano concetti e “implementazioni” già fatte più di 100 anni fa ovviamente su scala ridotta e con “tecnologie” completamente diverse.
Ecco un po di foto dell’evento: primo giorno e secondo giorno.
Aggiornamento (21/01/2013): corretti alcuni riferimenti ai nomi dei relatori su segnazione di Paolo Corti (grazie!) del quale vi segnalo anche il commento al post per ulteriori dettagli su GeoNode
GFOSS 2012 e OSMit 2012: un breve resoconto
Ecco un breve resoconto della tre giorni torinese di GFOSS 2012 e OSMit 2012 a cui ho avuto modo di partecipare.
Molti partecipanti (oltre 170 iscritti ….), interventi interessanti, un buon “fervore” sulle tecnologie GIS open source.
Nel mondo del GIS desktop direi che praticamente tutte le presentazioni hanno fatto riferimento a QGIS con la quasi totale assenza di altri attori (ricordo forse una presentazione che citava gvSIG, nessuna menzione di soluzioni alternative quali Udig o altri ancora. Anche l’utilizzo di GRASS, pur presente in diverse presentazioni, avviene spesso mediato da QGIS): viene quindi confermata la tendenza che vede QGIS una sorta di must de facto in questo campo.
Per il tier rappresentato dal livello data base questo è ampiamente coperto da POSTGIS. Rientra logicamente in questa categoria SQLite anche se gioca un ruolo leggermente diverso e per il quale di prefigura un possibile nuovo utilizzo.
A livello di soluzioni server enterprise la presenza più significativa è invece stata quella di GeoServer, anche se in una presentazione è stato citato QGIS Server come soluzione adottata.
Sul fronte mobile mi sarei aspettato una maggior numero di interventi di natura tecnica (soluzioni, framework , ecc … ), mentre ricordo solo un paio di interventi, uno di Alessandro Furieri, di inquadramento generale e più orientato agli standard OGC da usare su soluzioni mobile, e uno di Andrea Antonello (molto interessante), sull’evoluzione del mobile negli anni e della piattaforma mobile con accenno a GeoPaparazzi. Lo stesso QGIS per Android è stato dichiarato segnare un po’ il passo.
Completamente assenti invece presentazioni o accenni alle soluzioni cloud che invece si stanno affacciando anche sul mondo GIS: non le usa ancora nessuno in Italia? Possibile?
Anche se non sono riuscito a seguire tutte le presentazioni provo a riassumere e riportare alcune delle cose più interessanti, ovviamente a mio personale giudizio.
Uno dei primi interventi è stato quello relativo a QGIS di Paolo Cavallini che ha illustrato oltre alle caratteristiche già note del prodotto, quelle che saranno le prossime news e anche delle anticipazioni su caratteristiche funzionali future. A livello di news abbiamo:
- possibilità di usare scale di colore sia per dati vettoriali sia per dati raster
- una ristrutturazione della modalità di trattare i dati raster
- ricampionamento dei raster
- potenziamento della console Python
- integrazione di Atlas per fare serie di mappa
- miglioramento del supporto standard OGC
Per il futuro invece:
- ristrutturazione simbologie
- completamento etichette
- ristrutturazione sito e documentazione
- miglioramento integrazione SEXTANTE
- 3D Globe
- accesso ad ORACLE nativo
- WFST per QGIS Server
- supporto multithread
E’ confermato un rallentamento sulla parte QGIS per Android.
Anche la presentazione di Andrea Aime su GeoServer ha illustrato quelle che saranno le future evoluzioni del prodotto e precisamente:
- introduzione di linguaggi di scripting quali Python, Ruby, ecc .. per il WPS
- la possibilità di usare un solo geoserver per servizi diverse organizzazioni, enti, divisioni aziendali
- supporto png 8 con canale alpha: immagini più piccole ma di qualità, come con il formato png24
- supporto time ed elevation
- rendering transformation: calcolo isolinee o heat maps fatte al volo durante il rendering
- miglioramenti integrazione con GeoWebCache
- supporto del WFS 2.0 (standard INSPIRE) e supporto paginazione
- supporto XSLT
- chiamate asincrone su WPS
Si sta già lavorando sulla release 2.2.3 in cui si avranno:
- Aggancio per autenticazione: LDAP o base dati e supporto diversi sistemi di autenticazione (CAS)
- Configurazione di GeoServer su database
- GoeWebCache: possibilità di clustering
- Catalogue server in geoserver
Nel futuro ci sono ipotesi di:
- Supporto WCS 2.0
- Supporto NoSQL DB
A livello di presentazioni di natura tecnologica interessante quella di Francesco Izzi del CNR su GeoPlatform, progetto nato nel 2010 e disponibile su github costituito da un client basato su GWT e uno strato di servizi Java. Al momento è alla versione 1.5.
Alessandro Furieri nel corso della sua presentazione ha annunciato che per l’implementazione del nuovo standard OGC GeoPackage (GPKG) la scelta è caduta su SpatiaLite e questa è sicuramente la notizia tecnologia di maggior interesse in prospettiva (il nuovo standard dovrebbe uscire nella sua versione definitiva a fine 2012 / inizio 2013)
A livello di presentazioni relativi a progetti sicuramente da citare è stato l’intervento di ISTAT a cura di Francesco Di Pede dal titolo “Censimento 2011: dal dato areale al dato puntuale. Numeri civici, edifici e popolazione” in cui è stata messa enfasi sull’Anagrafe Nazionale delle Strade e Numeri Civici di sui tanto si sta parlando sul web in questo periodo. Sono stati presentati interessanti esempi di casi d’uso reali di questi e altri dati georiferiti in possesso dell’ISTAT (vie, edifici, civici, ecc …). Purtroppo continua a non essere chiarissimo quali, quanti e in quale modalità i dataset saranno resi disponibili, quindi se open data o meno.
Altra presentazione di progetto interessante è stata quella di Corrado D’Alessandro dal titolo Settimo Torinese con l’open source ottimizza la conoscenza del territorio. Il progetto è stato realizzato completamente con tecnologie open source e precisamente:
- Postgis 2.0
- QGIS Server 1.8
- OpenLayers in QGIS client
- GeoExt 3
- PHP
La palma del miglior progetto presentato però mi sentirei di darla a quella de “Il portale delle reti tecnologiche di Regione Lombardia: un esempio di tecnologia aperta per la condivisione di informazioni e dati sulle reti tecnologiche” (rif. http://www.ors.regione.lombardia.it/cm/home.html e http://195.254.250.104/gisclient/intro.php?topic=generic ), non tanto per la parte tecnologica, quanto per la completezza delle informazioni che sono rese disponibili dal progetto e consiglio chi interessato di provare a dargli un’occhiata.
Molto interessante anche il lavoro di ARPA Piemonte su “Acquisizione di misure nivologiche manuali georiferite tramite social media”, con un interessante utilizzo di Ushahidi, replicabile anche in altri contesti.
Nella giornata dedicata ad OSMIt le presentazioni più interessanti sono state quelle relative a:
- Geographike che utilizza OSM per fare business con una replica della base dati di OSM per l’Italia aggiornata giornalmente (modalità documentata sul wiki di OSM). Le tecnologie usate sono POSTGIS come data base, Mapnik integrato con MapProxy per la distribuzione delle tiles: la documentazione tecnica è stato dichiarato che sarà resa pubblica.
- Controllo dell’ortografia dei nomi delle strade realizzato da Daniele Forsi e disponibile via web www.forsi.it/osm/
